You have 47 data quality issues. You can fix 5 this quarter. Here's how to pick
You have 47 data quality issues. You can fix 5 this quarter. Here’s how to pick the right 5.
Most teams prioritize data quality fixes by which stakeholder complained loudest last week. That’s reactive triage.
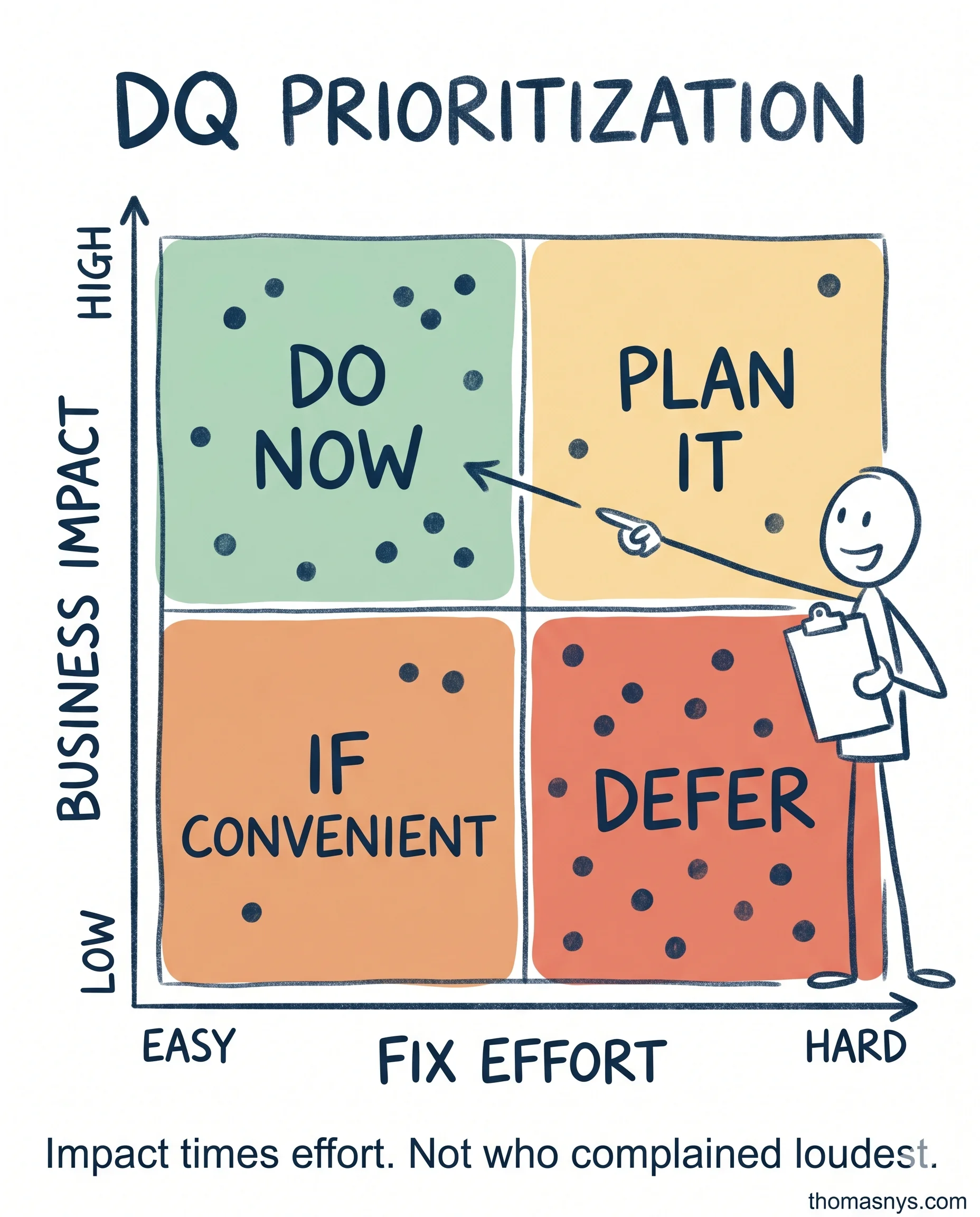
A working matrix: business impact × fix effort.
Four quadrants:
High impact + easy fix: do now. These are the wins. Schema mismatch breaking a board-level dashboard? One-day fix? That’s a do-now.
High impact + hard fix: plan it. These need actual engineering investment. Cross-domain reconciliation. Historical backfill. Customer ID consolidation. Plan them, scope them, fund them.
Low impact + easy fix: only if convenient. Don’t burn quarterly capacity on a 30-minute fix that nobody notices.
Low impact + hard fix: defer or ignore. The trap: these often get fixed first because they’re the most “interesting” engineering work.
Attach EUR values. “This DQ issue costs €12K/month in wrong attribution decisions” beats “this is bad.” Numbers make prioritization defensible.
Then ask the business owner what decision the data drives. If the answer is “we look at it sometimes,” it’s low impact. If the answer is “we re-allocate €500K of marketing spend on this number,” it’s high impact. The data quality matters in proportion to the decisions it drives.
Most DQ backlogs are 47 items long because nobody ever pruned. Build the matrix once. Cut the bottom-right quadrant entirely. The list becomes manageable.
What’s your most expensive data quality issue right now?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →