Wrong DE Hire Cost Matrix
A wrong data engineering hire runs you about three salaries by the time you count the ramp, the re-hire, and the work that stalled in between.
Time-to-hire for a senior DE already sits near three months. Getting it wrong roughly doubles that, plus the morale cost of a misfit nobody wants to name.
The mismatch is usually about role rather than talent. Two axes I map before any data hire.
What the work actually needs:
- Mostly building pipelines and shipping models? That’s an engineer.
- Mostly deciding structure, standards, and stack? That’s an architect.
- Mostly experiments and statistical questions? That’s a scientist.
What seniority the problem needs:
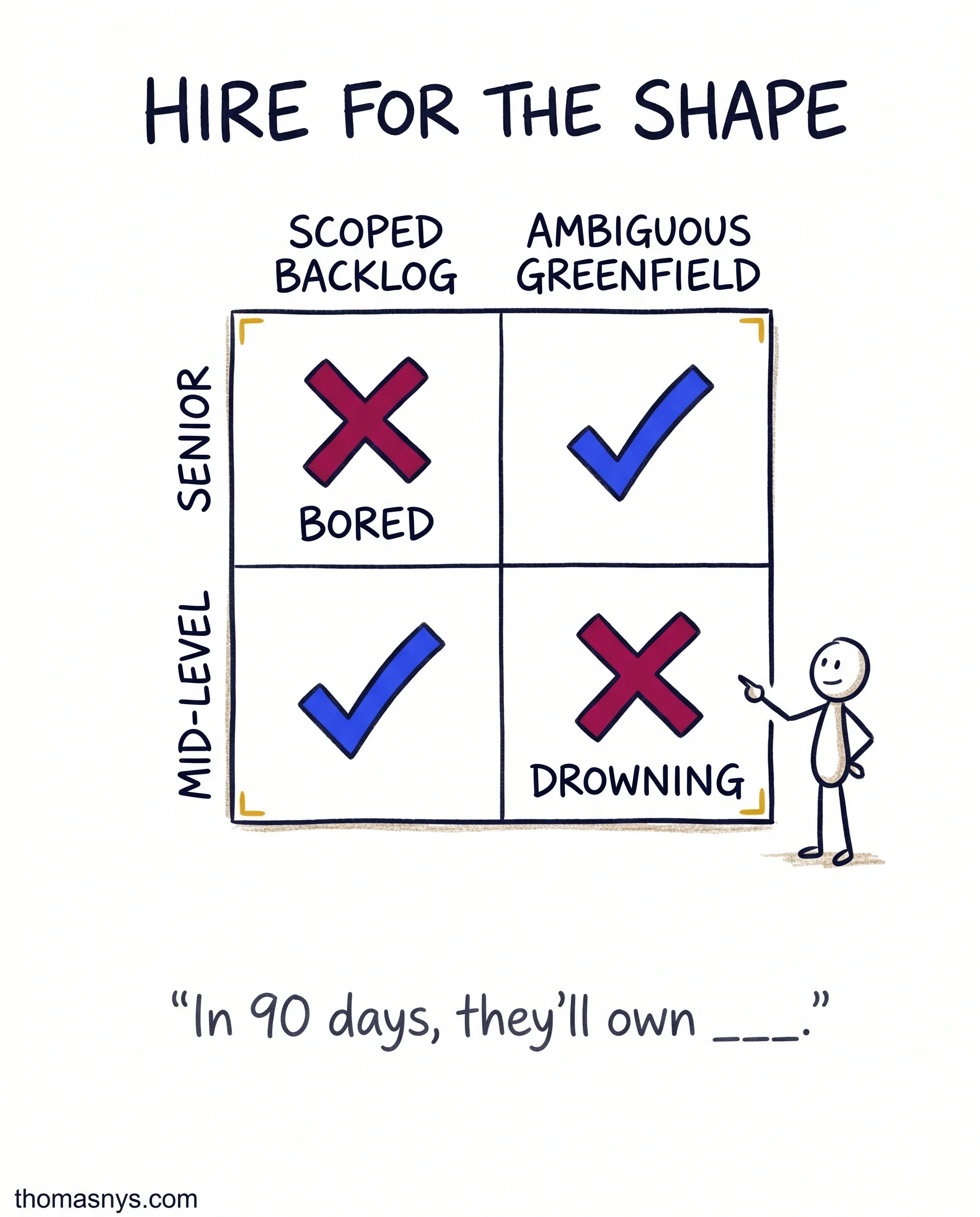
- A clear, scoped backlog someone executes? A strong mid-level fits. A senior gets bored and leaves.
- An ambiguous greenfield where someone has to define the problem? A junior drowns, and you pay in rework.
The expensive errors live in the corners. A data scientist hired to fix broken pipelines. A junior handed an undefined platform. A senior architect hired to grind a well-defined backlog. Each one looks fine on paper and ramps badly in practice.
Before opening the role, write one sentence: “In 90 days this person will own ___.” If you can’t fill the blank cleanly, that’s a definition problem, and no candidate fixes a definition problem.
Hire for the shape of the work. The impressive CV is secondary to whether the shape matches.
For your next data hire, can you finish the sentence: in 90 days they’ll own ___?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →