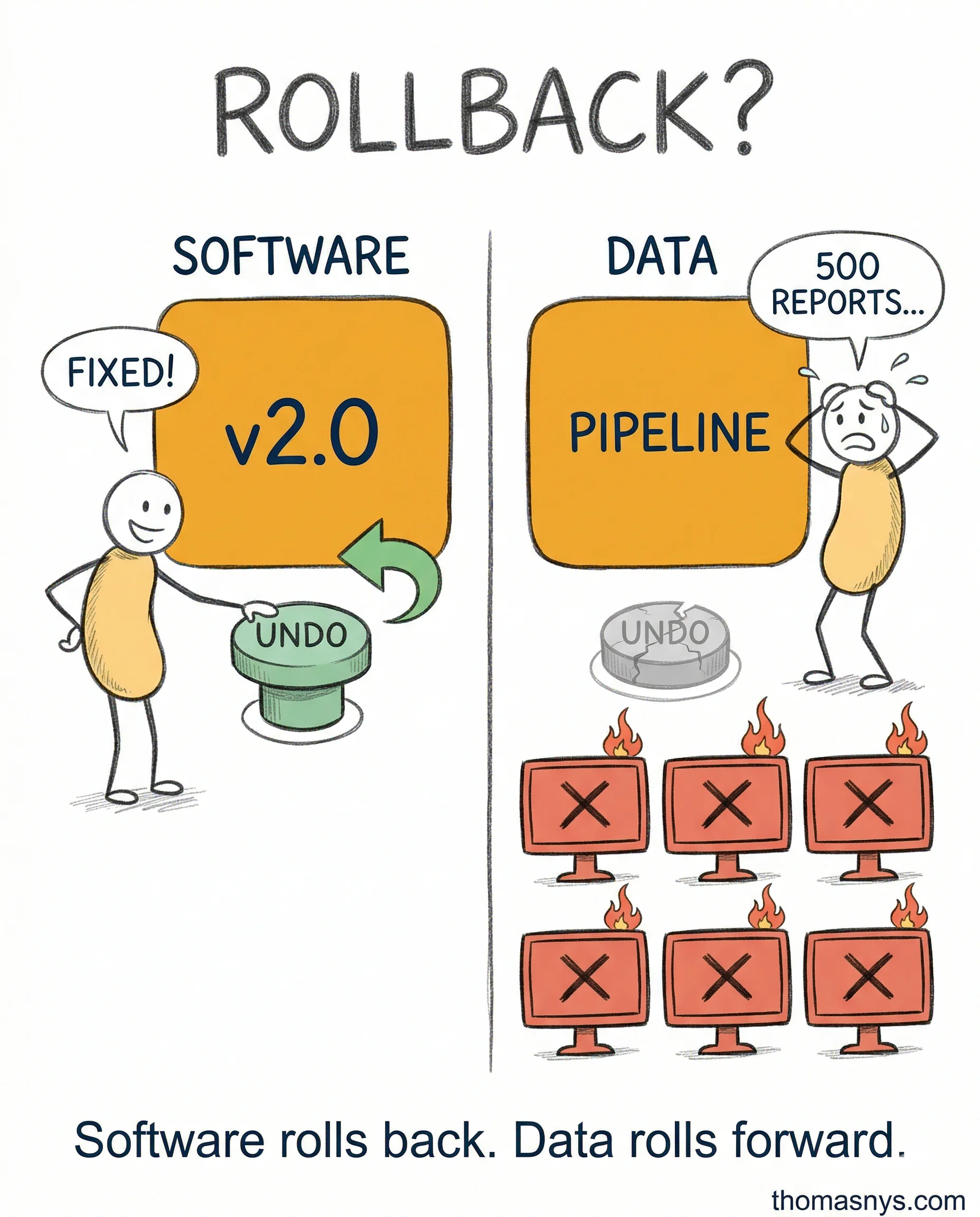
The DevOps playbook assumes you can roll back - data doesn’t work that way.
Software deployments are stateless. Something breaks, you revert. Done. Data transformations aren’t like that. You can’t undo corrupted data that’s already been served to 500 dashboards.
I used to think “flow, feedback, learning” would transfer cleanly. It didn’t. Three things kept breaking the model.
First, non-deterministic inputs. Software tests are repeatable. Data sources change schema, volume, and quality without warning. Your test passed yesterday. Today the upstream producer added a field and didn’t tell anyone.
Second, time as a dimension. Late-arriving data, out-of-order events, timezone bugs. None of that exists in the DevOps playbook.
Third, the feedback gap. In software, users file bugs. In data, consumers silently stop trusting your output. They build their own spreadsheets. You won’t hear about it for months.
I’ve changed my mind on this over the series. The principles are right. Flow, feedback, learning, safety. But data needs its own playbook built on those principles - not a copy-paste from software.
What’s the one DevOps assumption that broke down first in your data work?