The Lift-and-Shift Lie
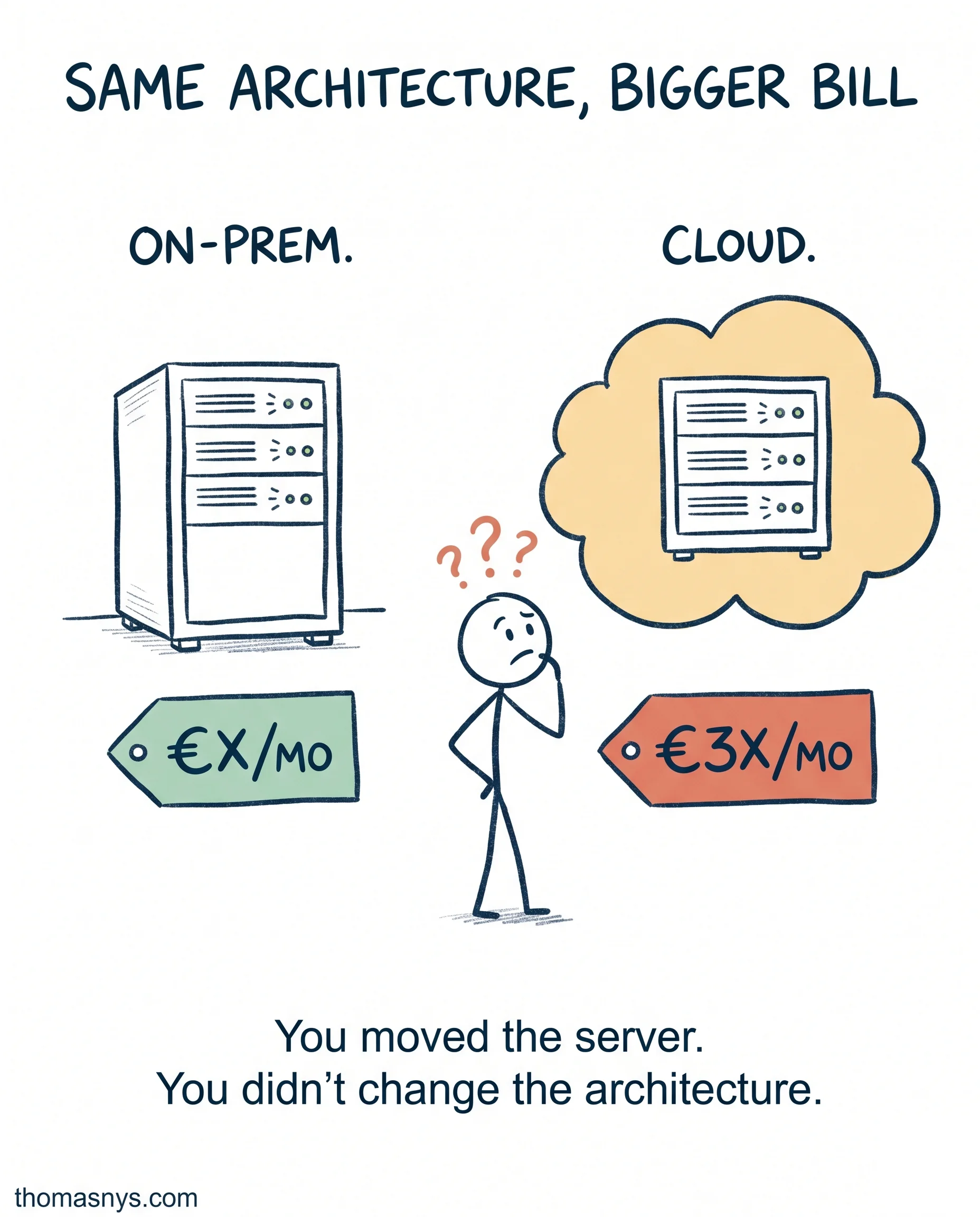
The cloud migration finished in March. By July the bill was 3x and nothing was faster.
I’ve seen this at four clients in the last two years. The pitch was always the same: move to AWS/Azure/GCP, retire the on-prem servers, save money, gain speed. The migration team did exactly what they were asked to do. Forklift the application, same code, same architecture, different hosting.
Cloud pricing rewards architecture designed for it. Auto-scaling, right-sized instances, ephemeral compute, managed services. On-prem architecture was designed for fixed capacity, vertical scaling, always-on servers.
When you lift and shift, you’re paying cloud prices for on-prem patterns. Always-on VMs. Over-provisioned databases. Fixed compute. All running on a pricing model designed for elastic workloads.
The bill goes up because the architecture doesn’t match the pricing model. The speed stays the same because the design is the bottleneck.
Lift-and-shift has one valid use case: buying time. Move first, modernize second, with a funded plan for the second part. Without that plan, the higher bill becomes permanent.
Three questions I ask any CTO post-migration:
- Which workloads are still running 24/7 that could be ephemeral?
- Which databases are over-provisioned because nobody right-sized after the move?
- Is there a funded modernization phase, or did the project stop at “we’re in the cloud now”?
What percentage of your cloud workloads were actually re-architected for cloud?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →