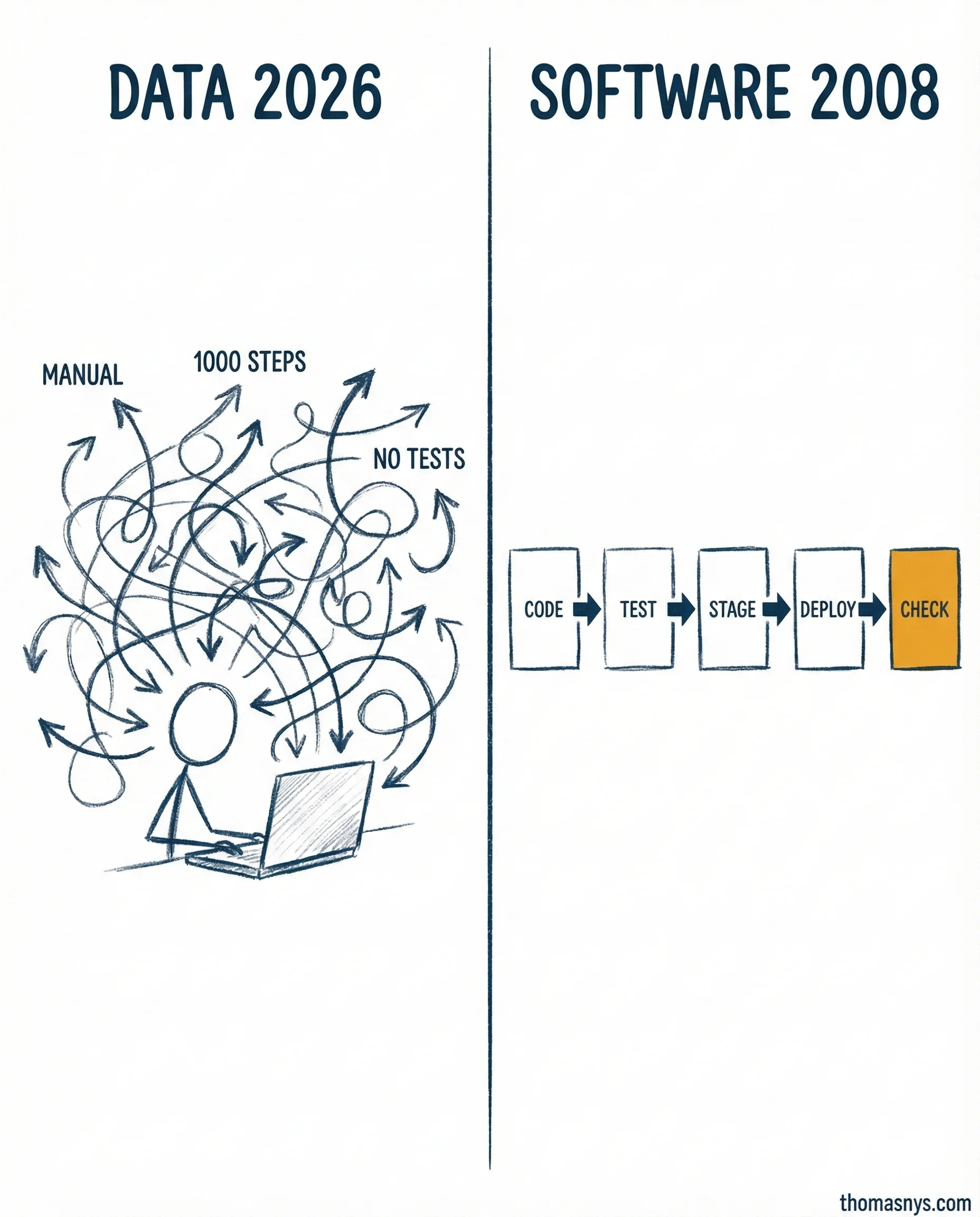
Your data team deploys to production the same way software teams did in 2008. Manually, nervously, with a 1000-step runbook nobody trusts.
Software engineering solved this problem a decade ago. The DevOps Handbook laid it out: automated pipelines from commit to production. Tests at every gate. Staging environments that catch problems before users do. In 2026, no serious software team ships code by hand.
Data engineering? Still stuck in 2008. Schema changes go straight to production without version control. Tests run “when someone remembers.” Staging environments for data models don’t exist at most teams I work with.
That’s a decade-wide maturity gap. And it’s not because the tooling doesn’t exist. dbt, Great Expectations, CI/CD for data - it’s all there. The gap is cultural. Data teams inherited a “scripts and cron jobs” mindset and never graduated to engineering discipline.
Here’s what catching up looks like: model change, automated schema and quality tests, staging validation, production deploy, observability confirming health. Each step gates the next. The way you ship is part of what you ship.
The teams that close this gap don’t just deploy faster. They sleep better. Fewer incidents, fewer rollbacks, fewer Slack fires at 11 PM.
Can you deploy a data model change to production in under an hour without manual steps?