When your data breaks, how long until someone notices? If the answer is “when the CFO calls,” you don’t have an incident response process.
Software teams solved incident response 15 years ago. PagerDuty, on-call rotations, runbooks, blameless post-mortems. A bug in production? Detected in minutes, diagnosed in under an hour, resolved before most users notice.
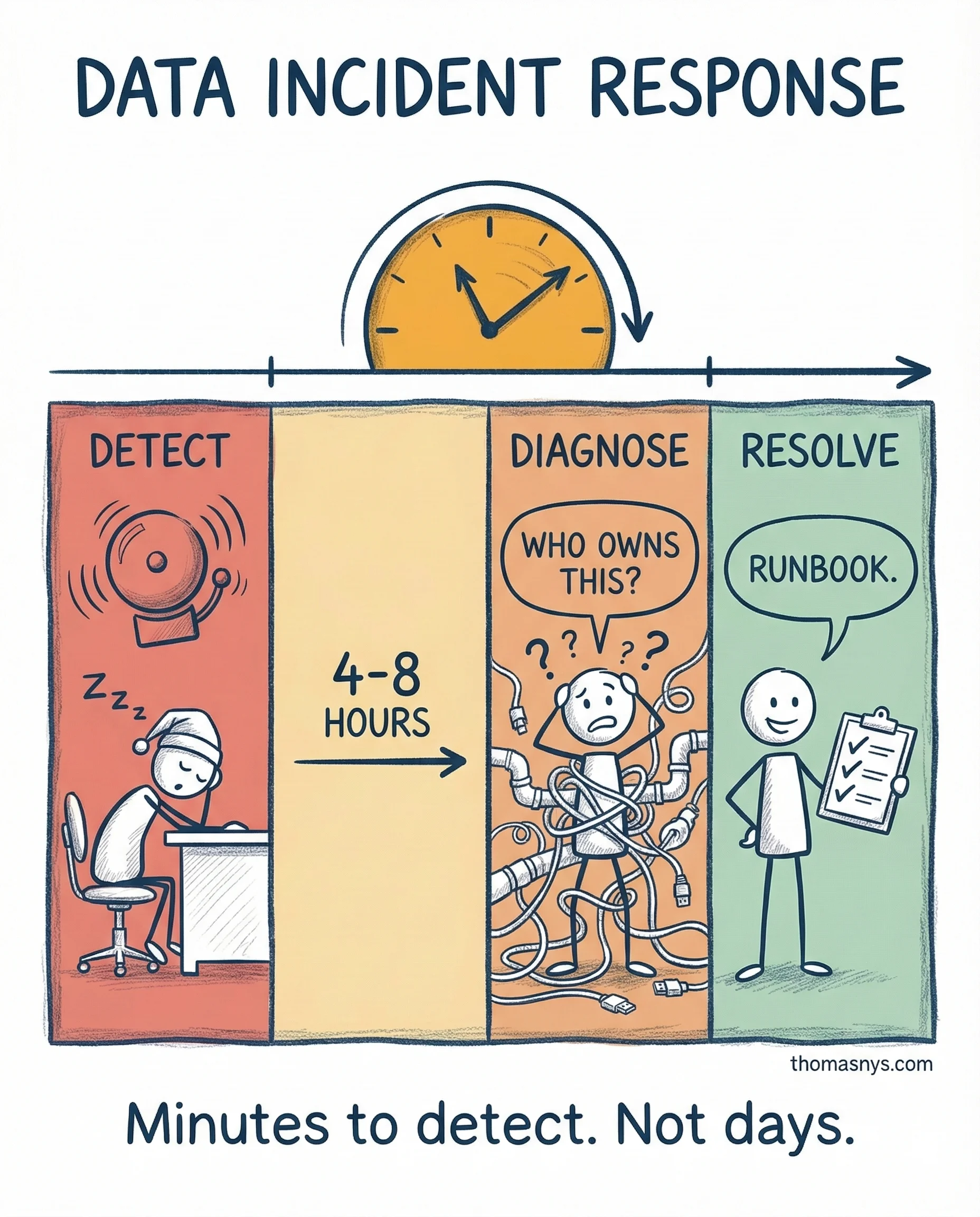
Data teams? Still in 2010. Most know if a pipeline ran. Almost none know if the output is correct. Detection means the CFO looking at a dashboard and saying “these numbers don’t look right.” That’s not detection. That’s luck.
The maturity gap is massive. Software teams monitor correctness - data teams monitor uptime. Software teams have runbooks per service - data teams have “ask the senior engineer.” Software teams do blameless post-mortems - data teams do “who ran that query?”
What closing the gap actually looks like: automated quality checks (row counts, schema drift, distribution changes, freshness) that catch anomalies before users do. Lineage tracking that turns a 4-hour investigation into 15 minutes. Clear ownership per pipeline with documented response paths.
The tools exist. The practices are proven. Data teams just haven’t adopted what software teams figured out a decade ago.
When was the last time your team ran a blameless post-mortem on a data incident?