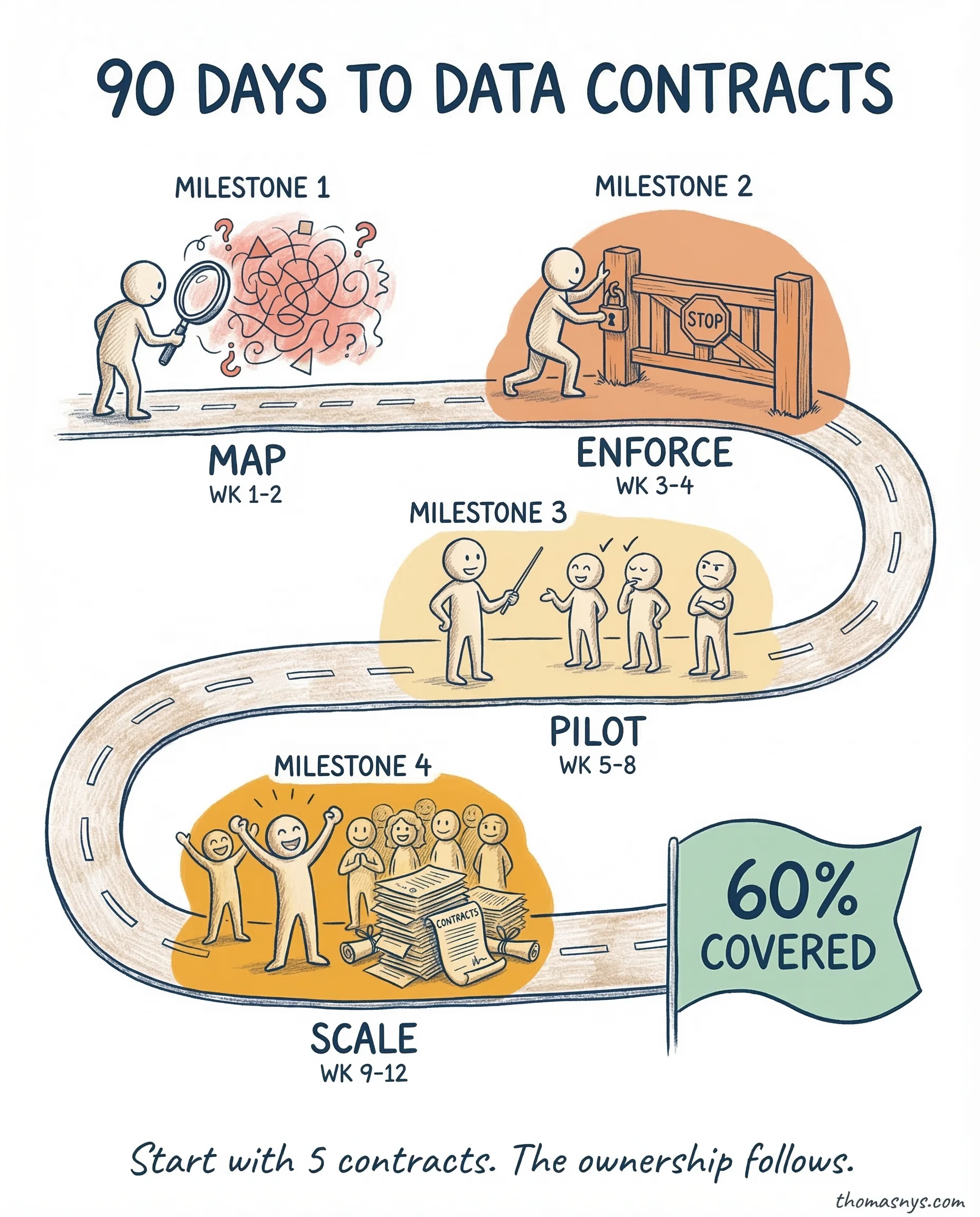
Data contracts sound great in theory. Here’s what it actually looks like to implement them - week by week, with the parts that almost derailed us.
Week 1-2: Identify your critical data products. Map who produces them and who consumes them. This sounds simple. It took two weeks because nobody had a complete picture. We started with the 10 most-used tables.
Week 3-4: Define the schema structure (YAML-based) and set up CI/CD enforcement in GitHub. Every schema change now requires a contract update. No contract update, no merge. This was the most important decision - make it impossible to skip.
Week 5-8: Pilot with engineering teams first. They understand schemas. They push back less. Five contracts went live. Two broke in the first week because the contract was too strict. Loosened tolerances, kept the structure.
Week 9-12: Scale to analytics and data science teams. Harder sell - they’re less used to schema enforcement. Focus on the benefit: “you’ll stop getting surprised by upstream changes.” Reached 30 contracts covering 60% of async data communication.
The result nobody expected: the conversation about contracts forced teams to document ownership for the first time. The contracts were the catalyst. The ownership was the real win.
How many of your data producers and consumers have a formal agreement on schema and quality?