The Batch Window That Ate A Weekend
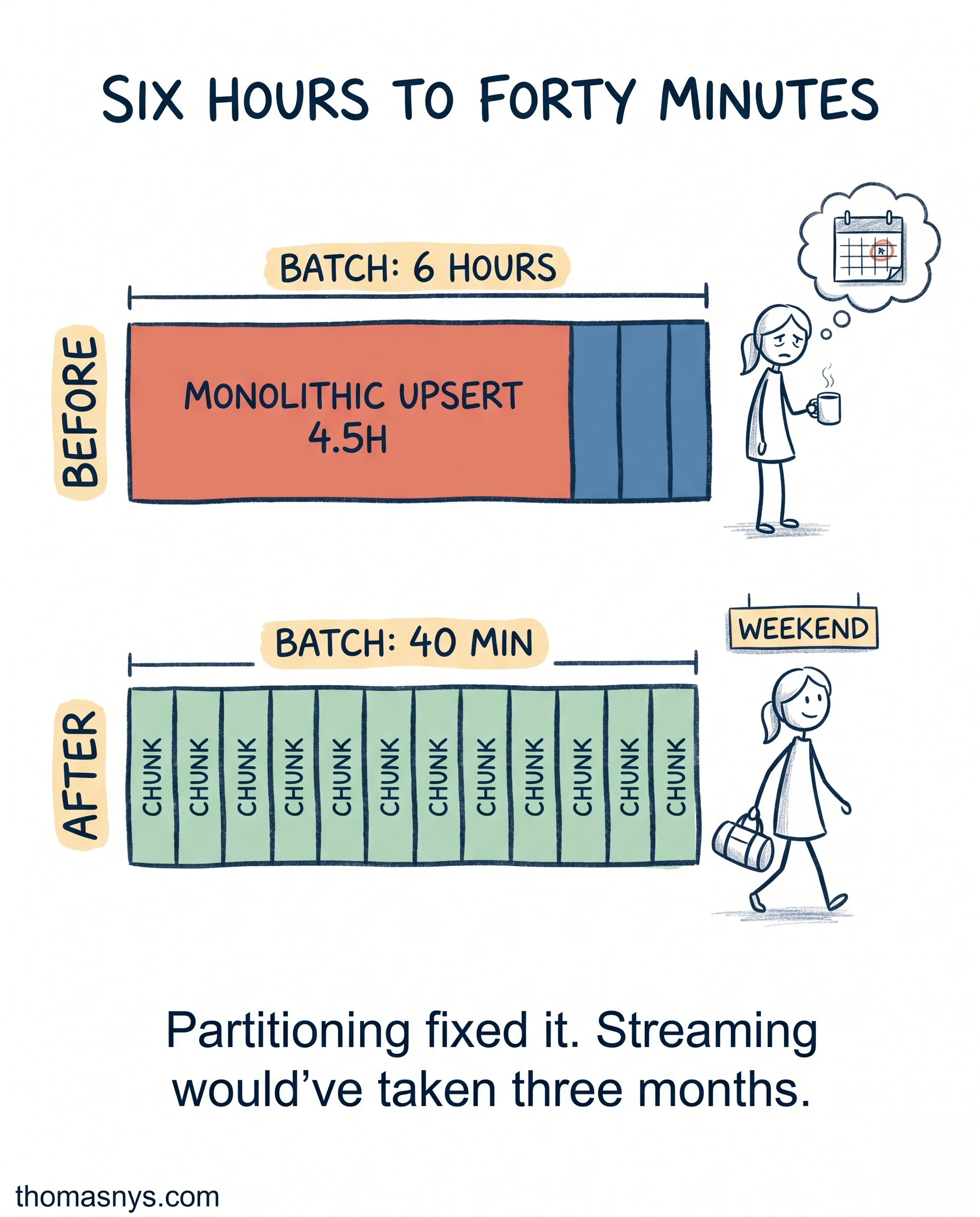
The six-hour batch was eating one engineer’s weekend every two weeks. Nobody had measured it.
A HealthTech client last year. The customer ingestion pipeline ran nightly. Six hours wall clock. Most nights it finished by 5am. Two or three nights per month it failed at hour 4, woke up the on-call engineer, and ate her Saturday until everything was reprocessed.
The first proposal on the table when I joined: move to streaming. Kafka, Flink, the whole thing. Cost estimate: 3 months of engineering plus €4-6K/month in new infra.
I asked a different question. What’s actually slow in the batch?
We pulled the run logs from the last 60 days. The answer surprised everyone: one stage took 4.5 of the 6 hours. A monolithic upsert against a table that had grown 30x in two years without partitioning. Everything else combined was 90 minutes.
Three weeks of work later:
- Partitioned the target table by ingestion date
- Split the upsert into 12 parallel chunks
- Added incremental logic so reruns processed only the failed chunk
Batch time dropped from 6 hours to 40 minutes. The failure rate dropped because each chunk was small enough to retry cleanly. Weekend on-call calls dropped to zero.
Total cost: less than €100/month in extra compute. Total saved: a senior engineer’s weekend, twice a month.
The teams I see jumping to streaming are usually solving the wrong problem. Real-time has its uses, but most “we need streaming” conversations are actually “we need partitioning and parallelism.”
Look at the run logs first. The bottleneck is almost never what you assumed.
What’s the slowest batch stage in your pipeline right now?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →