Privacy By Design In Pipelines
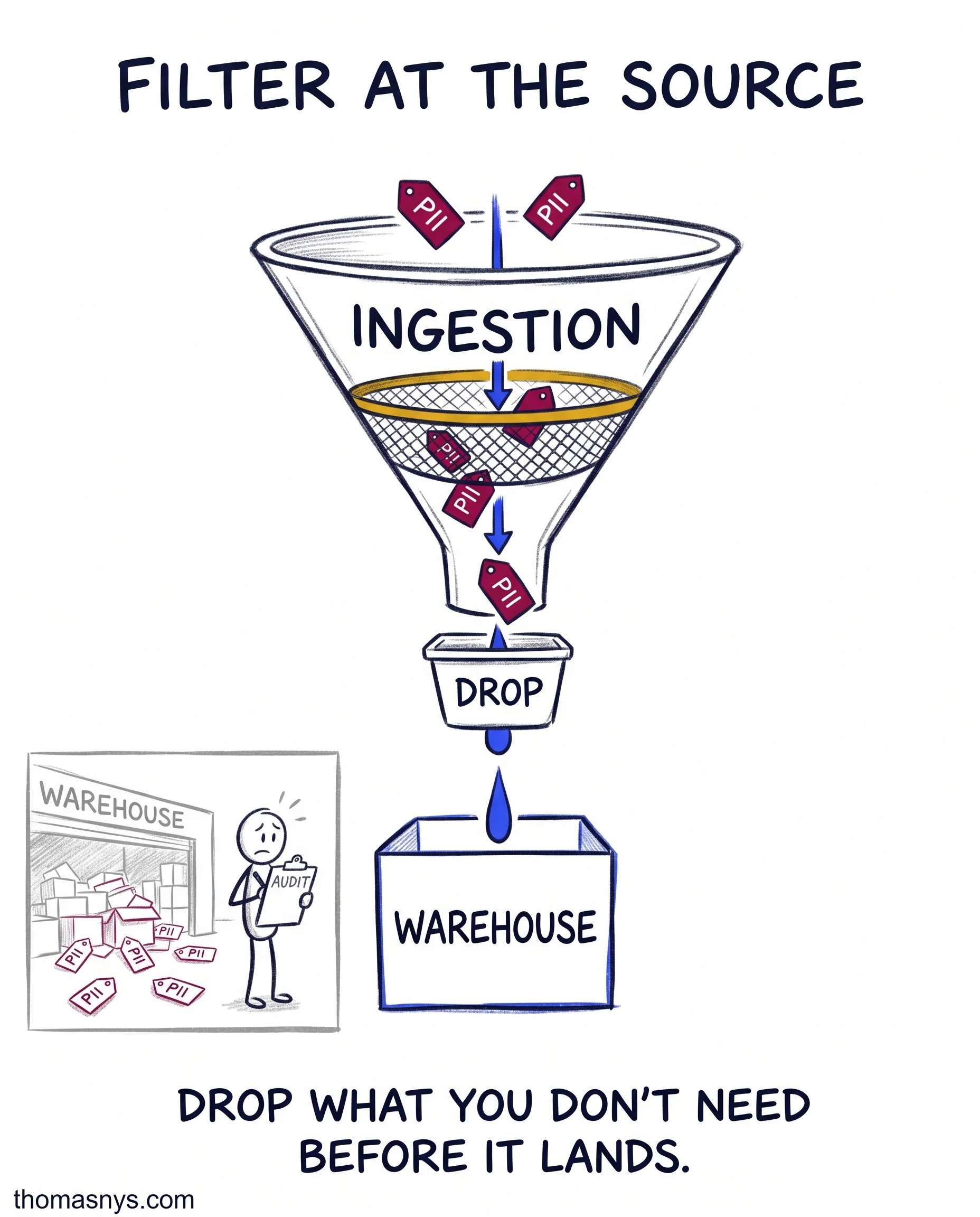
Most teams collect everything “just in case,” then try to add privacy when an audit looms. By then it’s in 40 tables.
By then it’s also in three backups and two BI tools, and clearing it out is a full project. The cheapest time to drop the PII you don’t need was before it ever landed in the warehouse. Every day after that, removing it is a migration with a risk review attached.
Privacy by design in a pipeline is mostly four habits, applied at ingestion:
- Minimize at the source. If a field has no named use, don’t ingest it. Default to dropping, not keeping.
- Separate identity from behavior. Pseudonymize early and keep the key mapping in one controlled place, not spread across every table.
- Set retention per dataset at creation, not “someday.” Raw events expire on a schedule the system enforces.
- Tag personal data where it lives. Every column carrying PII is labeled, so any later request (access, deletion, audit) is a query, not a manual hunt.
Done at ingestion, this is a few days of design work, and it serves GDPR and the AI Act from the same foundation. Both want the same things: know what personal data you hold, why, and for how long.
Retrofitted after the fact, the same work becomes a multi-month cleanup under deadline pressure, usually while a regulator or a customer is waiting.
A test for your current pipeline: can you list every column holding personal data with one query? If not, that’s where to start.
Can you list every column holding personal data in your warehouse with a single query?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →