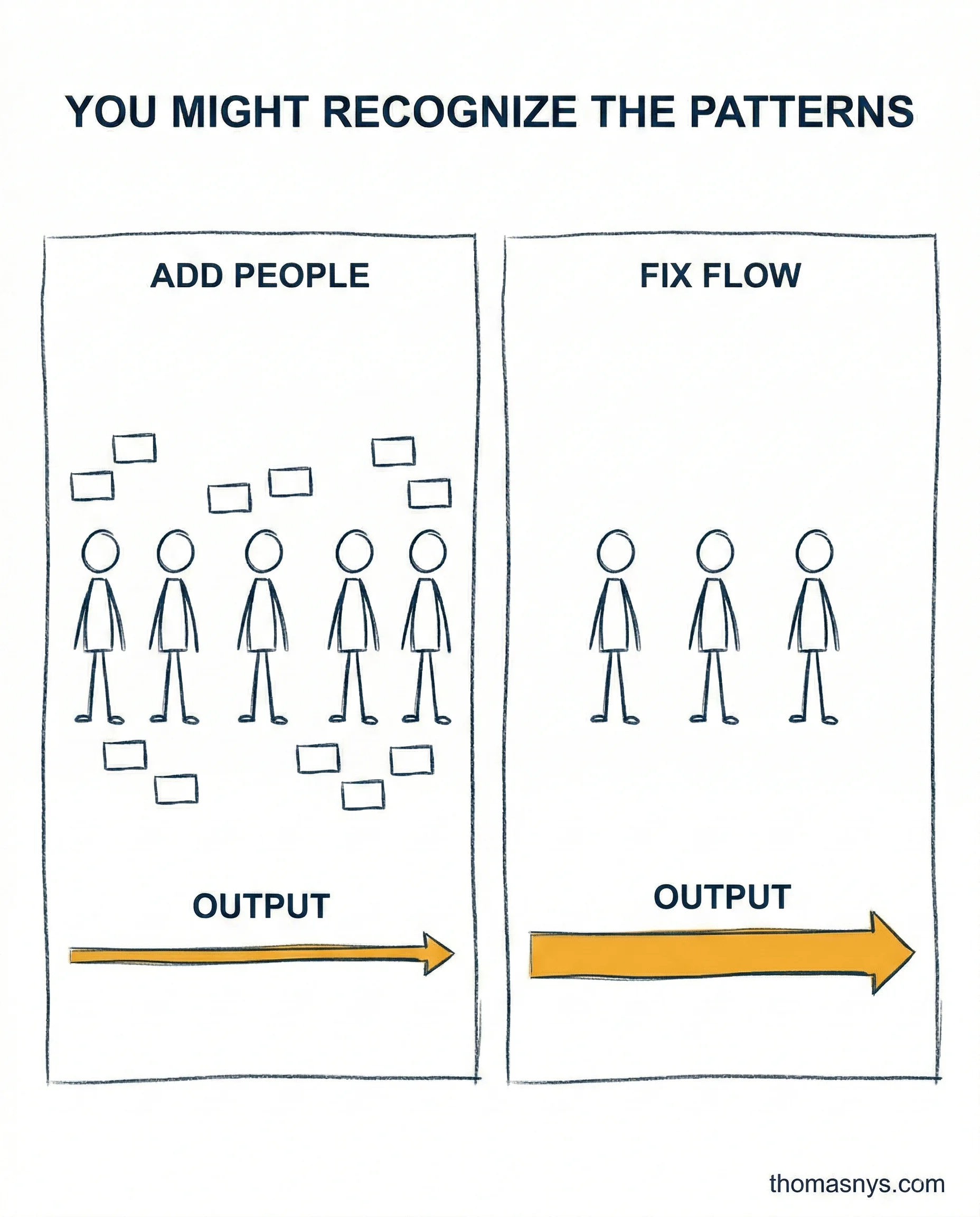
The Phoenix Project described a company drowning in unplanned work. Gene Kim called it Parts Unlimited. You might recognize the patterns.
Parts Unlimited had Brent - the engineer everything flowed through. Every critical system touched him. Deployment lead times measured in weeks. The team spent more time fighting fires than shipping anything. Gene Kim made it feel like fiction. It wasn’t.
Your data platform has the same patterns. One senior engineer who knows why that transformation job does what it does. Pipeline changes that take three days because nothing is tested and nobody’s sure what breaks what. A team spending 60% of sprints on incidents instead of planned work.
The insight Bill Palmer eventually gets: the bottleneck isn’t capacity. It’s flow. Parts Unlimited kept hiring, kept adding people, and kept getting slower. Data teams do the same thing. Another engineer won’t fix an architecture where 40 pipelines share one fragile ingestion layer with no contracts and no observability.
The other pattern: too much work in progress. Parts Unlimited had a dozen strategic projects all half-finished. Data teams have 80 pipelines, 15 active requests, and 6 “urgent” dashboards - all incomplete, all fighting for the same people. That’s not a resource problem. That’s a flow problem.
What percentage of your data team’s time goes to unplanned work versus planned delivery?