Ownership Vacuum After First Hire
The junior left in March. In May, marketing’s dashboard broke and nobody knew who to call.
A FinTech client late last year. They’d hired their first data analyst in 2024, who built most of the dashboards single-handedly. Quick growth, organic ownership. She left for another company in March. The team promoted from the analytics-engineering side to backfill. New person, new priorities.
Two months in, the attribution dashboard the CMO checked every Monday started showing wrong numbers. The new hire didn’t own that pipeline. Nobody did. The original analyst built it, shipped it, and her name was on it in nobody’s mental model except hers.
The team spent three days reverse-engineering what should have been a five-line fix. Three Slack threads, two postmortems, one CMO escalation.
The lesson cost them a week of senior engineering time. The lesson itself was free: when you scale past a one-person data team, ownership has to be explicit before it’s needed.
What I run with clients now after a first or second hire:
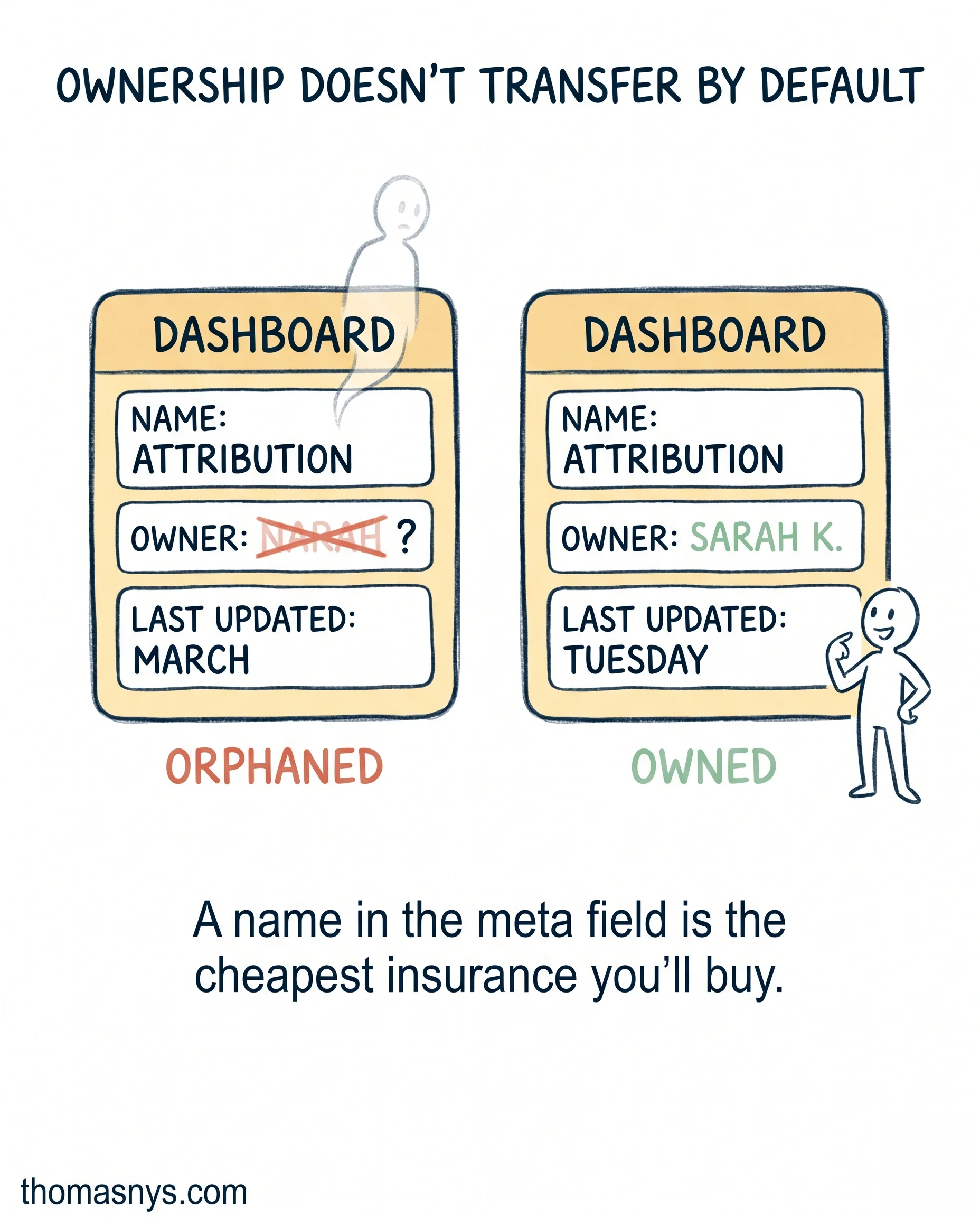
- One technical owner + one business SME per dataset / dashboard / pipeline. The engineer owns the contract: schema, freshness, the code that produces it. The business SME owns the definition: what counts, what doesn’t, which edge cases are intentional.
- Both names live in metadata: the dbt model file, the dashboard description, the README.
- When someone leaves, a documented handoff names the successor within 5 working days of resignation.
- Quarterly ownership audit: 30-minute meeting, scan the list, flag orphaned assets.
The cost is one meeting per quarter and a meta: field in the dbt config. The avoided cost is the next three-day fire drill.
If your most knowledgeable data person left tomorrow, how many dashboards go orphan?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →