Lakehouse Convergence Risks
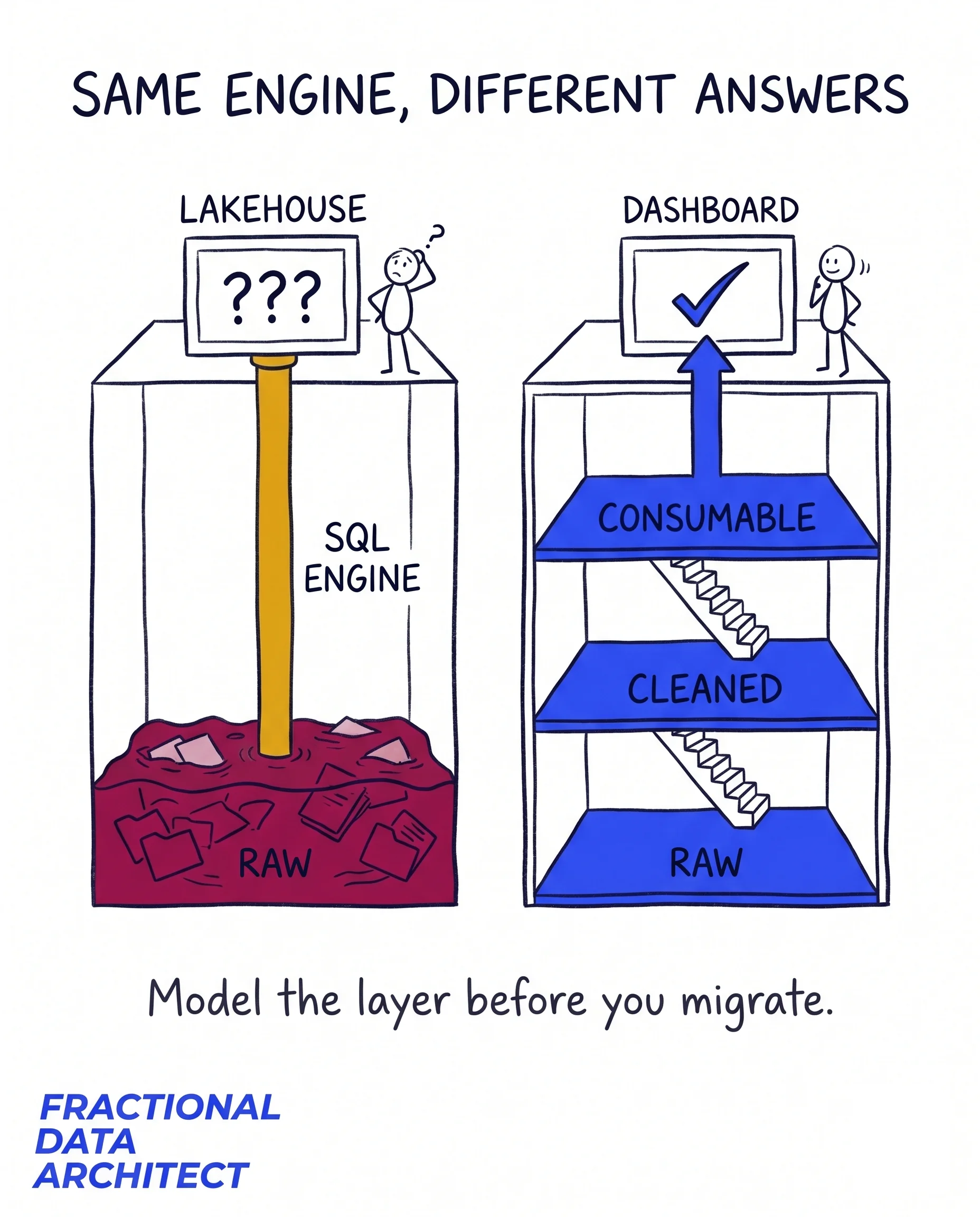
The lakehouse pitch is one platform for raw files and clean tables. The trap is inheriting the data lake’s oldest habit: land everything, model nothing, sort it out later.
The technology genuinely converged. Open table formats like Iceberg and Delta gave object storage transactions, schema evolution, and decent query performance. You can run warehouse-style SQL over files now. That part works.
The discipline didn’t converge with it. A warehouse forced some modeling up front, because loading data meant defining tables. A lake let you dump first and ask questions later. The lakehouse keeps the lake’s “dump first” ergonomics, so the old habit comes along for the ride.
What that looks like 18 months in:
- Hundreds of tables, no clear layer between raw and consumable.
- The same entity defined five ways, because nobody owns the modeled layer.
- Queries scanning raw files because there’s no curated layer to hit, so the bill climbs.
- “It’s all in the lakehouse” standing in for “we know what’s in it.”
The fix is old and unglamorous: a modeling layer, on purpose. Raw, cleaned, and consumable as distinct zones. Owners per domain. A rule that nothing reaches a dashboard straight from raw.
Convergence at the storage layer is real and worth having. It removes the copy-between-systems problem. It does not remove the need to model, and it quietly hides that need behind a query engine that’ll happily scan a mess.
If you’re moving to a lakehouse, decide the modeling layer before the migration, not after the swamp forms.
In your lakehouse, is there a clear line between raw and consumable, or does the dashboard query whatever it finds?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →