Idempotency In Orchestration Failures
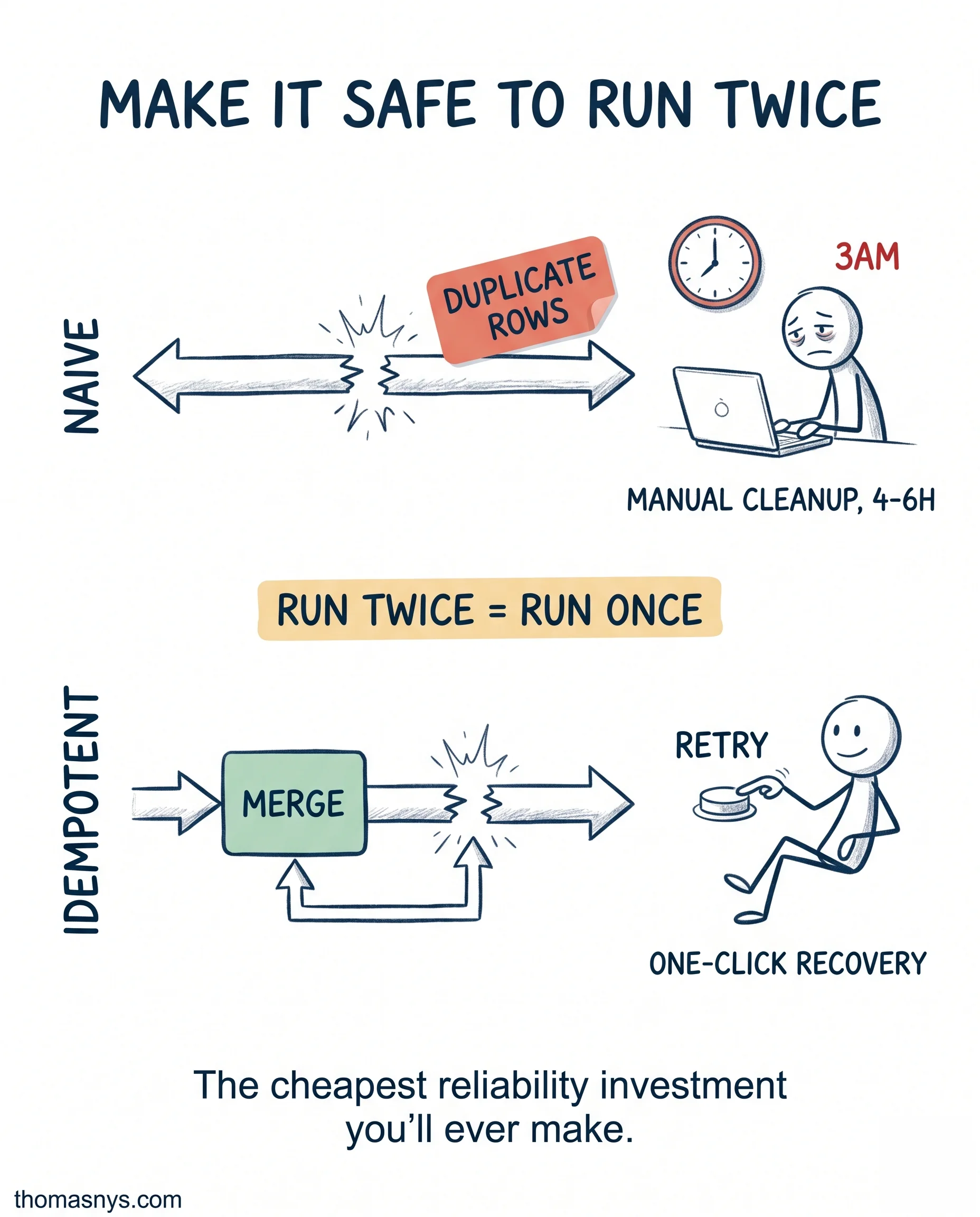
Your pipeline failed at 3am. The on-call engineer is now paid to clean up duplicates.
The pattern I see at most scaleups when an orchestration job fails partway through:
- Half the data is in the warehouse, the other half isn’t
- Retrying the whole job double-inserts the rows that already landed
- The on-call engineer manually runs SELECT DISTINCT queries at 3:30am to figure out what’s safe to re-process
- Recovery takes 4-6 hours
The jobs themselves aren’t idempotent. Run them twice, get different results.
Idempotent design means: running the same job twice produces the same end state as running it once. No duplicates. No half-states. Same outcome.
How you actually get there:
- MERGE / UPSERT instead of INSERT: keys deduplicate naturally. SQL warehouses give you this for free.
- Time-window partitions: each run targets a specific date range. Re-running yesterday’s job replaces yesterday’s partition. Doesn’t touch today’s.
- Run IDs in target tables: every row tagged with the run ID that produced it. Re-running a failed run deletes that run’s rows first, then re-inserts.
- Checkpoint state in a dedicated table: jobs know which steps completed. Restart from the failed step, not the beginning.
The migration to idempotent pipelines is usually 2-4 weeks for a scaleup with a dozen production jobs. The first time the team retries a failed job in a click instead of paging the on-call engineer, the investment pays back.
A signal you need this: anyone on your team has “manual cleanup after pipeline failure” in their actual job description.
Is your most critical pipeline safe to re-run without thinking about it?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →