Vertical scaling is adding RAM. Horizontal scaling is adding servers. One has a ceiling. One doesn’t.
Snowflake, BigQuery, Databricks - they all auto-scale horizontally. That part’s solved. You’re probably already paying for it.
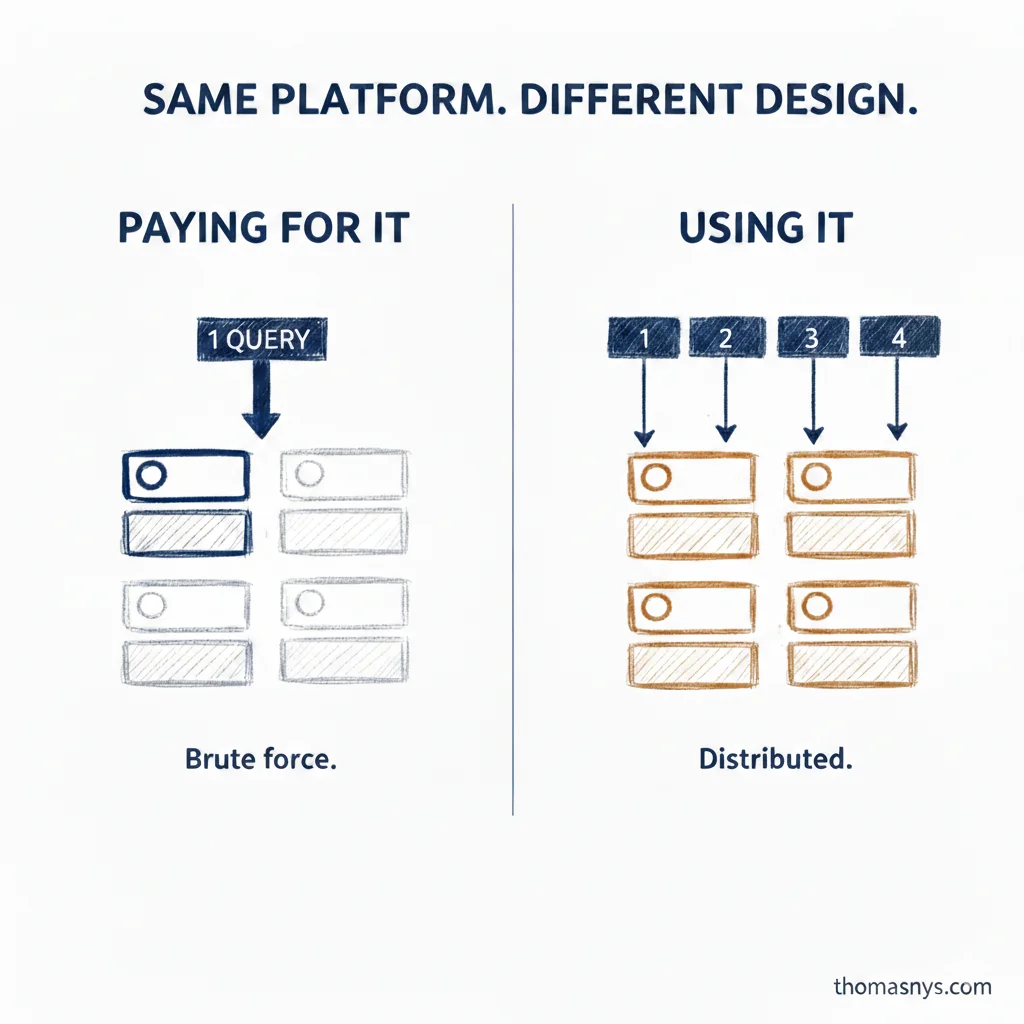
But here’s what I keep running into: the platform scales, the pipelines don’t. Teams migrate to a cloud-native warehouse and keep writing queries that assume a single node. Monolithic transformations. No partitioning strategy. One giant dbt model that touches everything.
The platform can throw more compute at it. So the query finishes. But you’re burning credits on brute force instead of distributed execution. That’s not scaling - that’s paying more for the same bottleneck.
The fix isn’t in the platform. It’s in the data model and pipeline design. Partition by what you filter on. Break transformations into stages that can run in parallel. Design your queries to let the optimizer distribute the work.
I’ve changed my mind on when to think about this. Not when you hit the ceiling - by then you’re mid-growth and short on time. Think about it when you pick the platform.
Is your architecture built to scale up, or to scale out?