Your data team switches between four tools during an incident. That’s about to change.
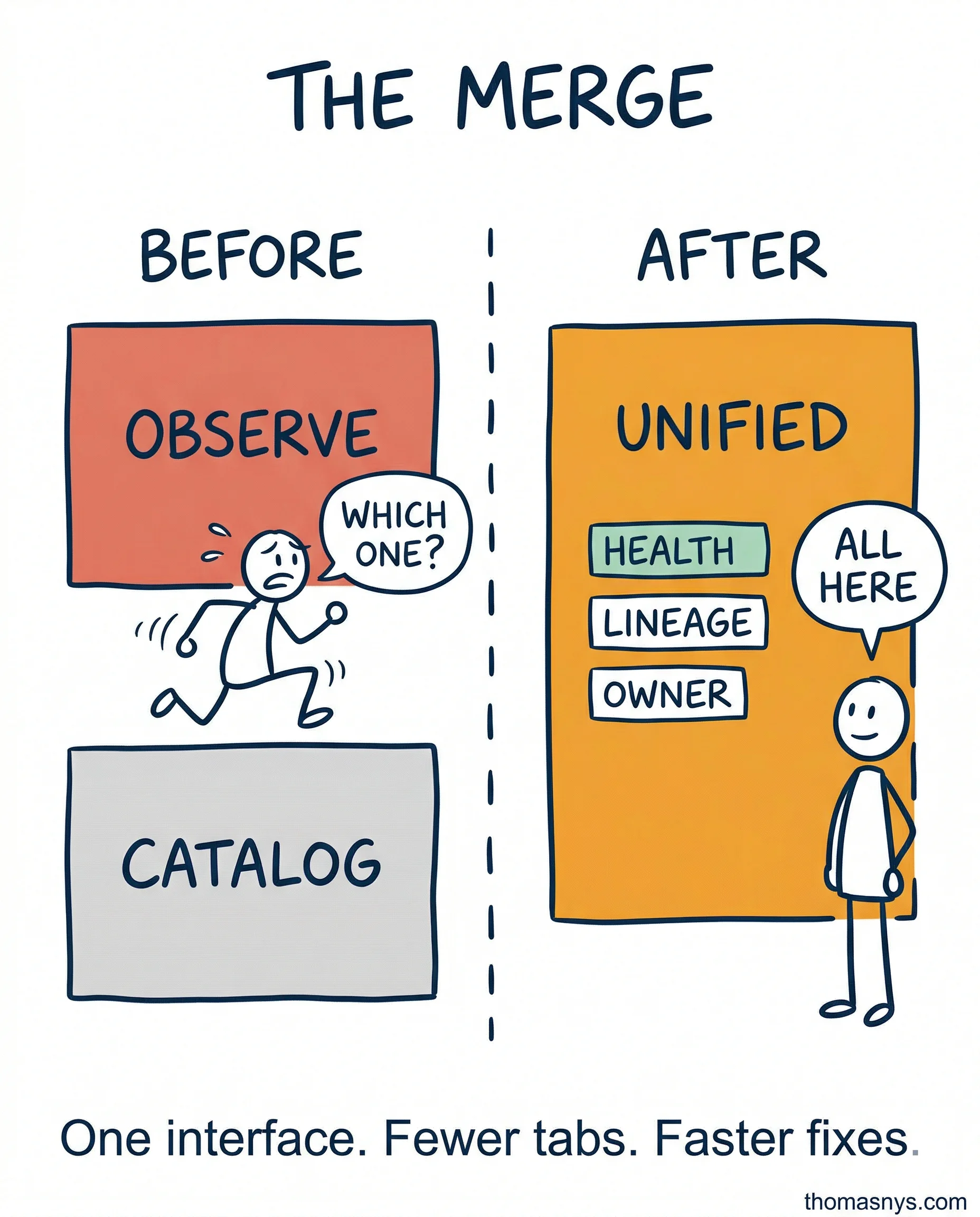
Pipeline breaks at 8 AM. Engineer opens the observability dashboard - freshness alert on a key table. Switches to the catalog to check lineage. Three downstream dashboards affected. Switches to Slack to find the owner. Turns out the owner left the company two months ago. Forty-five minutes gone before anyone starts actually fixing the problem.
I watched this exact sequence at a client last month. Four tools, four context switches, zero progress on the actual issue.
The shift happening now: unified metadata layers that connect discovery and monitoring. Alert fires, you see lineage, ownership, and downstream impact in the same view. You know who to call and what’s affected before you finish your coffee.
Atlan, Databricks Unity Catalog, OpenMetadata - they’re all moving this direction. Catalog and observability in one layer instead of two.
I’m not saying every vendor will nail this. Most convergence plays are messy in year one. But the direction is clear, and teams that plan for it now will spend less time tab-switching and more time actually fixing things.
How many tools do you switch between during a data incident?