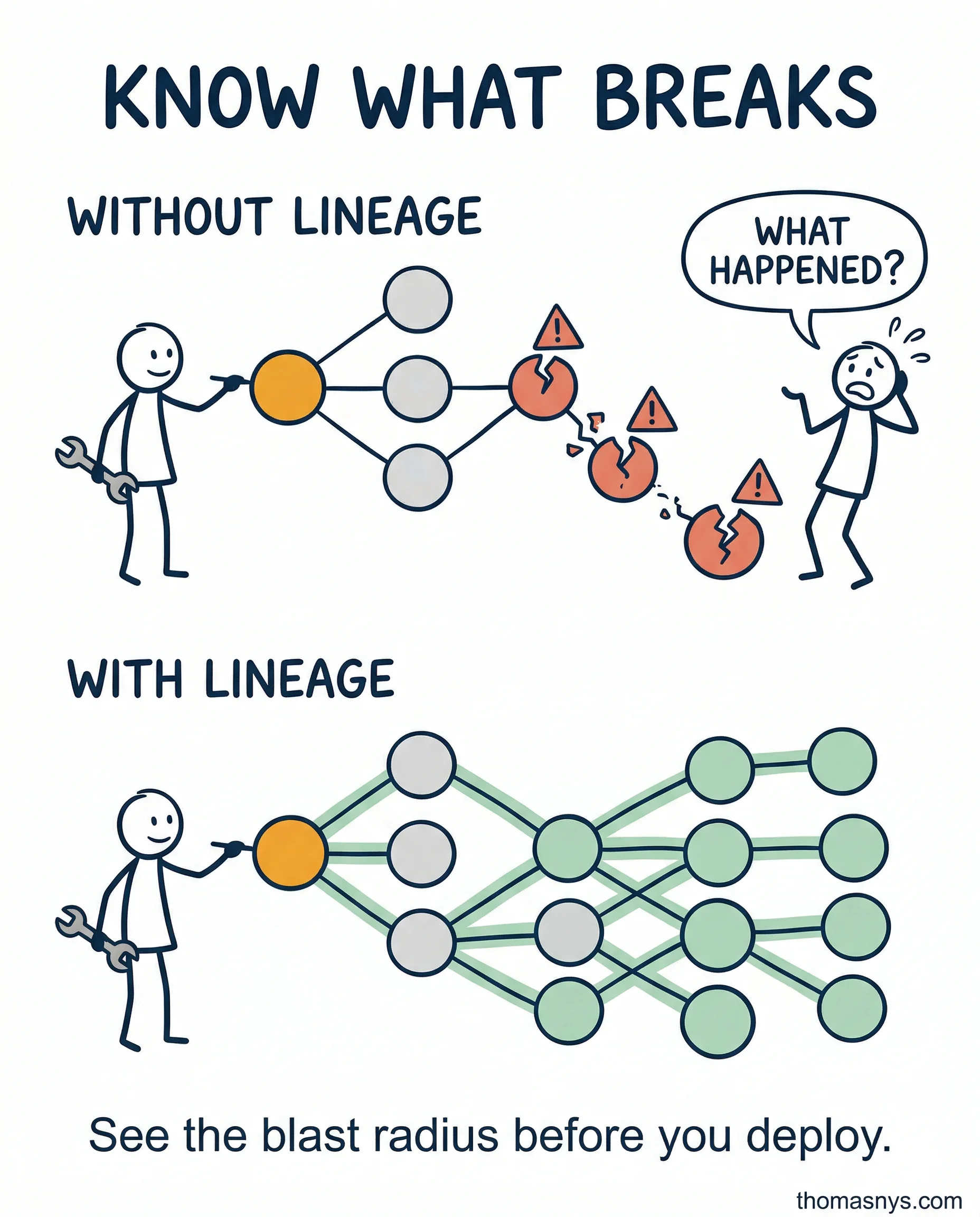
Without data lineage, every schema change is a game of “what did we just break.”
A client renamed one column in a source table last quarter. Seemed harmless. It broke three dashboards, two dbt models, and a downstream report the CFO uses every Monday. Nobody knew until the Monday meeting.
Data lineage used to be a nice-to-have. Something you’d get around to “after the migration.” In 2026, it’s table stakes.
Without it, every change is a risk assessment you can’t actually make. You’re guessing which reports depend on which tables. You’re pinging Slack channels to ask “does anyone use this field?” You’re deploying on Friday and praying.
With column-level lineage, you know exactly what breaks before you touch it. dbt gives you model lineage out of the box. OpenLineage captures runtime lineage from Airflow and Spark. Most commercial platforms offer it too.
A practical 30-day plan: Week 1-2, instrument your dbt project and orchestrator. Week 3-4, map critical data flows manually for the gaps. Week 4, connect it to your data catalog.
It’s not a massive project. It’s four focused weeks. And every schema change after that comes with a blast radius you can actually see.
What’s the last time a schema change broke something downstream that nobody expected?