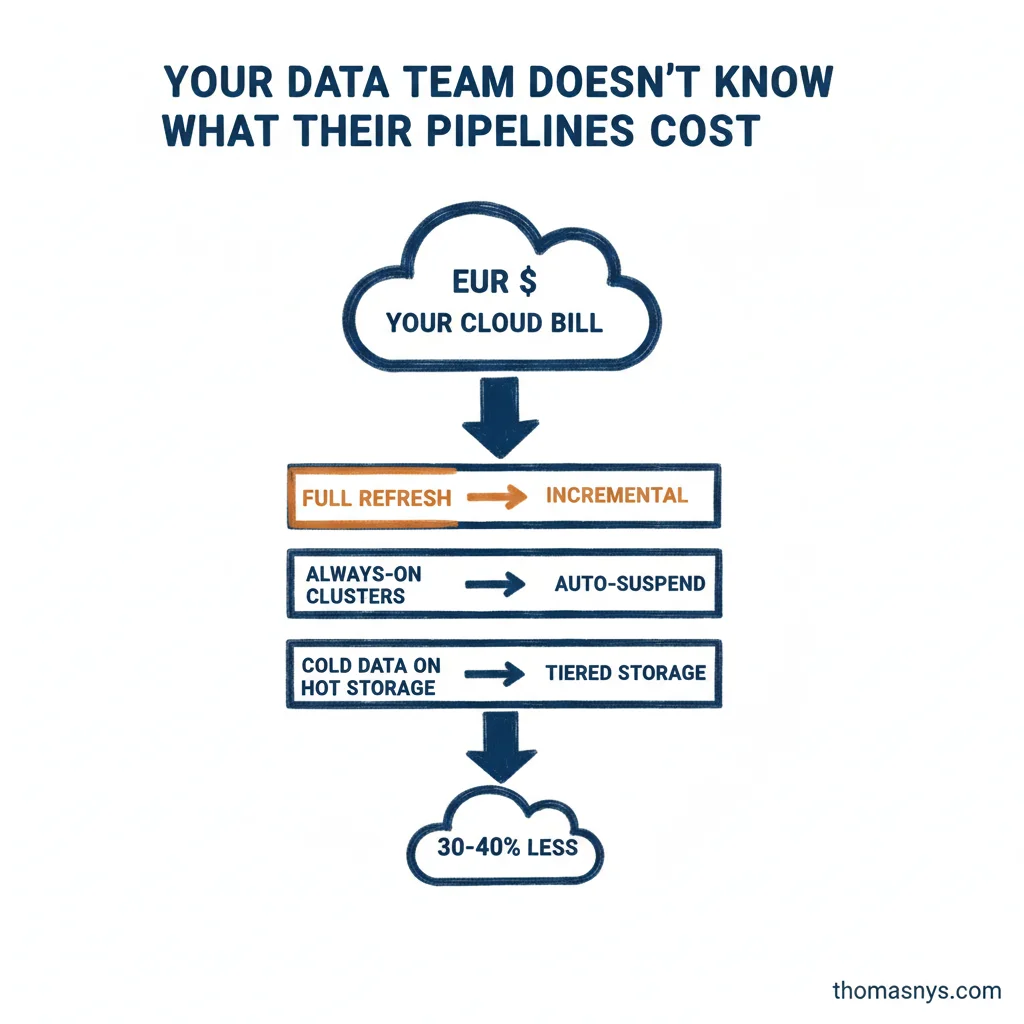
Your data team doesn’t know what their pipelines cost. That’s the first problem.
I asked a data engineering lead last month: “What does your most expensive pipeline cost per run?” Blank stare. Nobody had ever looked.
Turns out, one pipeline was doing a full table refresh every night when less than 1% of the data actually changed. Switching to incremental took an afternoon. The bill dropped by more than half.
This is the FinOps for Data gap. For years, the data world operated on “spend what you need, we’ll sort it out later.” Later never came. Now budgets are tightening and CFOs want to know why the Databricks bill is EUR25K/month.
Three places I always look first:
- Full-refresh jobs that could be incremental
- Dev/test clusters left running 24/7 because nobody set auto-suspend
- Inappropriate storage tiers that treat cold data like hot data
Most teams can cut 30-40% of cloud spend without paying down on features. Not by being clever. Just by measuring what they’re actually using.
Nobody enjoys the first audit. But the bill after makes it worth it.
When’s the last time someone audited your data platform’s cloud costs?