Contract-First Data For Cross-Team Handoffs
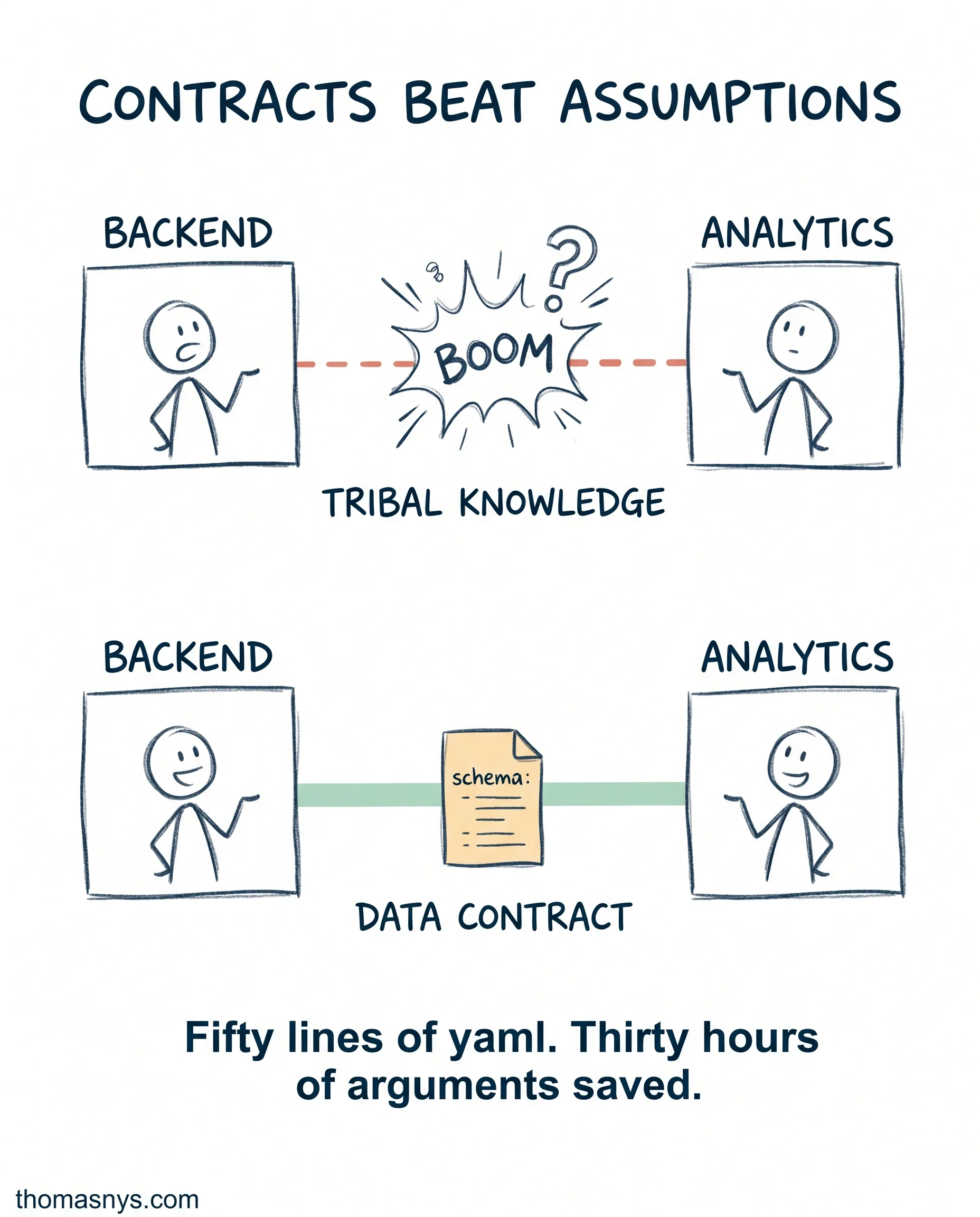
Most cross-team data fights are caused by an undocumented assumption upstream.
Backend ships a schema change. Analytics dashboard breaks. Marketing’s attribution numbers shift by 12% overnight. Three Slack threads, two postmortems, and one all-hands later, nothing structural changes. The next deploy will do it again.
A data contract is what the next deploy needs. More code review won’t catch it.
A data contract is a yaml file (or json, your choice) sitting in the producing repo. It defines:
- The schema (columns, types, nullability)
- Quality expectations (uniqueness, freshness, distribution bounds)
- The SLA (how often it ships, when it can break)
- The owner (one person)
- The consumers (who’ll be affected when it changes)
When backend wants to change the schema, the contract requires a deprecation notice and a migration window. The downstream team gets notified. The breaking change becomes a coordinated rollout instead of a surprise.
Most teams skip contracts because “it’s overhead.” Then they spend three hours every week reverse-engineering what upstream changed.
The math: a contract takes 30 minutes to write and 5 minutes to update. The arguments it prevents cost hours per incident. Break-even is one incident.
Start with your highest-traffic table. Write the contract. Add a CI check that fails the PR if the schema drifts without a version bump. Iterate.
Does your most critical dataset have a written contract, or a tribal one?
Fractional Data Architect helping startups and scaleups build data platforms that scale.
More about Thomas Nys →